
A travers la publication de 4 articles, nous partageons notre expérience et notre vision du Data Product Management. Dans ce deuxième article, nous expliquons pourquoi il est important d’intégrer du Product Management en Data Science, puis nous détaillerons comment le faire. Enfin, dans une dernière partie, nous nous intéresserons à l’agilité adaptée au développement de produits data.
Les produits data en échec
La majorité des entreprises a conscience aujourd’hui du potentiel énorme des produits data. Malheureusement, leurs équipes se lancent souvent dans des développements ambitieux qui s’étalent dans le temps (plusieurs années parfois) et qui avancent de manière déconnectée du métier et de ses utilisateurs finaux. Cela mène alors soit à l’abandon du produit, soit à la mise en production d’un produit data inutilisable, en décalage avec le besoin, qui a coûté beaucoup d’argent et qui décrédibilise totalement l’utilisation de la donnée.
Voici quelques chiffres pour illustrer nos propos :
- 87% de produits Data Science ne partent jamais en production
- 77% des entreprises déclarent que l’adoption des métiers de la big data et des produits data reste un défi majeur.
- 85% des projets de produits data ne parviennent pas à franchir les étapes préliminaires.Source : https://www.datascience-pm.com/project-failures/
Les produits data ont donc tendance à échouer. Mais pourquoi ?
A travers nos missions, les Hubvisors ont identifié cette liste non exhaustive d’explications :
Des limitations techniques
- Problème de données : absence de la bonne donnée, pauvre qualité, volume insuffisant … Sans surprise, la donnée, c’est la base du développement de tout produit data.
- Incapacité de mettre en production et/ou d’assurer la maintenance : le passage et la gestion du RUN. La livraison d’un produit peut paraître comme la fin d’une aventure mais ce n’est en fait que le début et cela est valable pour les produits classiques également. Mais cette phase de run pour un produit data est particulièrement difficile et doit être anticipée : avoir la bonne équipe et les bonnes compétences, maintenir l’infrastructure, capacité de mise à l’échelle …
Des problèmes de méthodologie et d’organisation
- Organisation non optimisée et recrutement difficile.
- Collaboration complexe entre les profils métiers et les profils data : il manque souvent un lien entre ces deux typologies de profils pour favoriser une bonne communication (spoiler alert : les Data Product Managers).
- Décalage entre le produit livré et le besoin utilisateur : le produit ne répond pas à un problème. Cela est dû à un manque d’exploration en amont du lancement des développements mais également à un manque de dialogue régulier et d’inclusion des utilisateurs dans la construction du produit data.
- Méthode de gestion de projet inadaptée : envisager le développement d’un produit data de la même façon qu’un produit classique est une erreur. Vous l’aurez compris, on oublie le cycle en V et les projets à rallonge. On use et abuse de l’Agilité adaptée aux particularités des produits data.
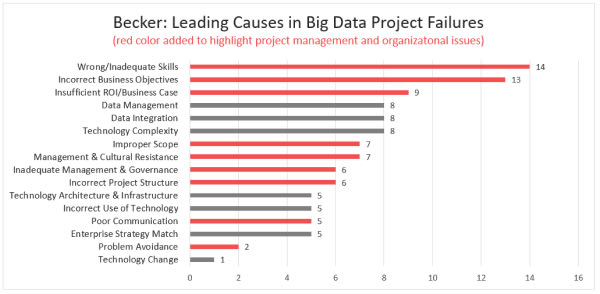
Raisons pour lesquels les projets Data échouent__Source:
C’est pour résoudre une partie de ces problèmes qu’entre en jeu le Product Management, et plus exactement le Data Product Management : une manière adaptée d’appliquer les méthodes du Product Management pour proposer et livrer des produits data utiles, performants, appréciés, et recommandés.
Le Product Management : la solution pour la construction des produits data
Le Data Product Management est une approche conçue pour faire face aux enjeux d’incertitude de la recherche tout en garantissant un time to market optimisé qui répond aux exigences de production. L’objectif est d’apporter un maximum de valeur aux utilisateurs finaux qui vont utiliser, parfois sans le savoir, le produit data développé.
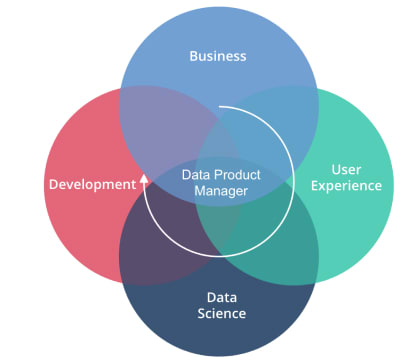
_Cycle du Data Product Management_Source : Hubvisory
Le Data Product Management bénéficie à tous :
- aux utilisateurs qui voient leur quotidien amélioré
- aux équipes de développement qui pourront exploiter pleinement leurs compétences et bénéficieront de la reconnaissance qu’ils méritent
- au leadership qui aura investi intelligemment dans le développement de produits innovants et qui proposera une avance sur la concurrence !
Explorer - Penser et prioriser un produit data en fonction de son apport de valeur
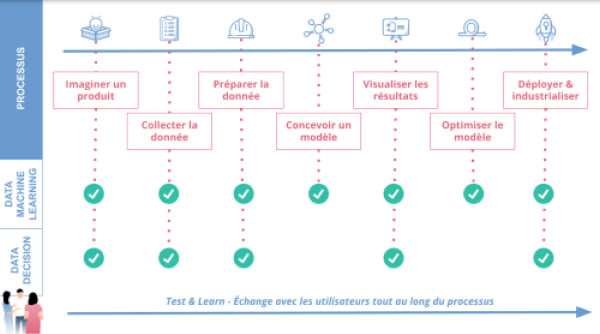
_Processus Data Product Management_Source : Hubvisory
Dans le schéma 2 ci-dessus, on aborde ici la phase 1: Imaginer un produit.
Lancer le développement d’un produit data sans une phase de réflexion et d’étude mène souvent à du gaspillage de ressources, de compétences et de temps.
Pour ce faire, voici quelques pistes pour vous permettre d’explorer une nouvelle idée de produit data. A la fin de ce travail, vous aurez toutes les informations vous permettant de lancer ou non le développement d’un tel produit.
1.Formulation de la problématique utilisateur : sous forme d’ateliers métier pour bien saisir leur besoin, premiers échanges avec des profils tech data, formalisation de canvas fonctionnels et techniques (adaptés aux produits data et qui, comme tout canvas classiques, évolueront tout au long du cycle de vie du produit data).
L’objectif est de vérifier que le produit data en question répond à une réelle problématique, de préciser les utilisateurs finaux, les solutions envisagées, les KPIs, les risques …
Louis Dorard, ingénieur chez Dataiku, propose le Machine Learning Canvas, inspiré du Lean Canvas qu’on utilise beaucoup en Product Management. Ce canvas permet de faire le lien entre le Machine Learning et un cas d’usage, un besoin utilisateur:
- Sur quelles données se base le produit ?
- Comment utilise-t-on les prédictions fournies par ce produit ?
- Comment s’assurer que le produit perdurera ?
Par exemple, nous avons mené une mission au sein d’un Data Lab où l’idée était de développer rapidement des Proof Of Concept pour tester la valeur de différentes idées de produits data. Nous nous sommes appuyés sur le Machine Learning Canvas pour décrire chaque POC et les prioriser les uns par rapport aux autres.
2.Recherche utilisateur : sa réalisation permet de vérifier les hypothèses métier, de recueillir les éléments utiles au développement du produit (règles métiers, gouvernance, délais…). S’appliquent alors les méthodes classiques de User Research (voir paragraphe suivant “Ecouter”).
3.Wireframing & prototypage : quand cela est possible, c’est un excellent moyen de collecter du feedback utilisateurs. Cela se fait plus facilement pour les produits de Data Decision qui prennent la forme de visualisation mais l’exercice est aussi intéressant, certes moins évident, pour les produits Data Science car cela permet de projeter l’utilisateur.
4.Analyse des données : une première analyse aide à dérisquer la faisabilité technique du produit en vérifiant les données (sa disponibilité, son accessibilité, sa qualité, sa quantité pour répondre au besoin) et à s’informer afin de permettre dès à présent des choix stratégiques dans la conception du produit.
📚 Lire notre article sur la vision produit.
📚 Lire notre article sur le wireframing
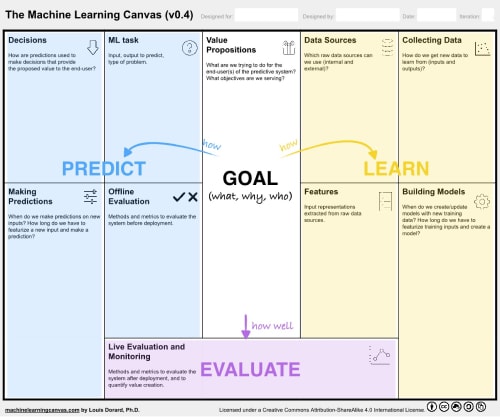
_Machine Learning Canvas_Source :
📚 Pour aller plus loin
Lors de ces étapes préliminaires, établissez une définition du succès de votre produit centrée sur vos utilisateurs : pourquoi votre produit data va-t-il rendre plus heureux vos utilisateurs ? plus engagés, plus satisfaits ? A tel point qu’ils iront recommander votre produit. Anticipez aussi les effets secondaires : quel impact une prédiction erronée (un faux positif par exemple) va-t-elle avoir sur votre utilisateur ?
Prenons l’exemple de Google Flights qui recommande le meilleur moment pour acheter ses billets d'avion. La définition du succès de ce produit data est le fait d’acheter au bon moment au bon prix. Un effet secondaire d’un faux positif, par exemple avoir prédit qu’un prix n’allait pas augmenter alors que finalement c’est le cas, peut avoir un impact non négligeable sur la vie d’un utilisateur et donc sa satisfaction (par exemple : annulation d’un projet de voyage, de retrouvailles avec des proches …). Identifié, on peut alors déjà prévoir et réfléchir à une solution pour éviter ou minimiser ces situations : par exemple, calculer un indice de confiance des prédictions et en dessous d’un certain seuil, décider de ne pas afficher ses recommandations.

Source : Conférence Google “Designing Human centered AI products”
Une question inévitable qu’il faut également se poser : est-ce qu’une solution non-data science peut répondre au besoin identifié ? Si l’on est capable d’expliquer en quoi la data est nécessaire pour répondre de la meilleure manière à un besoin (exemple : un produit classique ne propose pas une précision suffisante et est trop complexe à maintenir au vu du nombre d’utilisateur important qui le sollicite).
Explorer, c’est prendre le risque d'abandonner le projet à chacune de ces phases et de ne pas se lancer dans le développement d’un produit mais n’est-ce pas mieux que de perdre un an et du budget sur la réalisation d’un produit qui ne sera pas utilisé ?
Explorer, c’est aussi se laisser l’opportunité de pivoter et de faire la différence !
Alors, convaincu.e.s ? Abordons maintenant l’importance d’une bonne recherche utilisateur avant tout lancement de développement d’un produit data.
Ecouter - Les données au service d’un besoin utilisateur
Nombreuses sont les équipes data, parfaitement qualifiées et animées par la passion des mathématiques, des statistiques, de la visualisation, qui livrent des produits qui ne sont finalement pas utilisés et ne trouvent pas leur public … De plus, dans le cas des produits Machine Learning, les algorithmes qui sont conçus sont souvent directement intégrés aux applications centrales, ainsi le produit data souffre dans certains cas d’une absence d’interface utilisateur. Le Data Product Management permet alors de remettre l’utilisateur au centre pendant tout le processus de construction du produit data en échangeant avec lui et en recueillant ses feedbacks.
Mais alors comment écouter ses utilisateurs ?
En Product Management, il est important de récolter les besoins utilisateurs lors de la construction d’un produit (Discovery & Build) mais également tout au long de la vie de ce produit (Growth & Run). Mesurer les comportements des utilisateurs permet de piloter son développement.
Pour bien comprendre ses utilisateurs, coupler deux approches UX permet de limiter les erreurs d’interprétation :

Recherche utilisateur - quantitative vs qualitativeSource : Hubvisory
Approche quantitative
Elle permet de mesurer des actions d’utilisateur (Où ? Quand ? Combien ?). La data est un des éléments clés de la recherche UX, particulièrement pour cette approche :
- Elle est objective et neutre : leur collecte automatique fait qu’elle n’est pas biaisée.
- Elle est collectée de manière invisible et donc non intrusive pour l’utilisateur.
Plus il y a de données, plus les tendances sont représentatives. Les produits data (Machine Learning surtout) pour lesquels l’interaction avec les utilisateurs est moins évidente peuvent paraître trop techniques pour avoir recours à cette approche. Mais les clics, les vues, les funnels, les algorithmes… représentent bien un comportement, un besoin utilisateur.
Voici quelques exemples d’outils pouvant être utilisés : Google Analytics, Hotjar, Mixpanel… Hotjar permet par exemple d’enregistrer une session complète d’un utilisateur.
Cette collecte neutre permet de mettre en lumière le quoi mais donne peu d’informations sur le contexte. De plus, la donnée se limite à un environnement où les utilisateurs sont connectés. Mais nombreux sont les actions, les expériences, les comportements qui ont lieu hors ligne. Il faut alors combiner l’approche quantitative avec une approche qualitative pour identifier le pourquoi.
Approche qualitative
Elle permet de comprendre les motivations de l’utilisateur (Pourquoi ? Comment ?). Produit data ou classique, la démarche reste la même et se révèle une mine d’or d’informations. Cela peut prendre la forme d’interview utilisateur, de shadowing, de focus groupe, de test utilisateur, questionnaire / demande de feedback en ligne (reviews), personas … Malheureusement, cette approche est souvent négligée voire oubliée dans le cas des produits data.
Exemple : lors d’une de nos missions data qui traitait du développement d’un produit Data Decision (Analyse) autour des performances des opérations commerciales, l’organisation d’interviews utilisateur avait lieu 1 an après le démarrage des développements des Data Scientists et Analysts. Sur 12 personnes interviewées, 10 n’utilisaient pas le produit data proposé : nous nous rendions compte que l’importance pour les utilisateurs n’était pas telle ou telle fonctionnalité (filtre, calcul complexe d’une statistique …) mais plutôt la profondeur et la fraîcheur des données disponibles. En effet, les utilisateurs souhaitaient des informations sur les performances des opérations commerciales quasi en temps réel et avec un historique de plusieurs années pour permettre la comparaison. Dans ce cas, les retours des utilisateurs ont redonné du sens en définissant une nouvelle vision produit, en comprenant mieux le métier des utilisateurs et les données dont ils ont besoin et en identifiant les fonctionnalités prioritaires.
Itérer
L’itération est la meilleure façon de proposer de la valeur au produit data développé. Plutôt que de construire un modèle aux performances parfaites et de le sortir qu’une fois qu’il est “prêt”: l’idée est de proposer des releases régulières apportant des améliorations avec de la valeur. De plus, en délivrant rapidement et périodiquement, cela permet d’obtenir l’adhésion et la confiance des parties prenantes et des utilisateurs qui se renforcent au fil des livraisons.
Cela étant dit, intéressons-nous aux frameworks de gestion de projets à mettre en place lors du développement de produits data.
L’agilité : la solution pour les équipes data ?
Dans le cas de la construction d’un produit data, il s'agit d'extraire des informations utiles à partir de données brutes et de :
- soit les transformer et trouver la meilleure façon de les faire parler / les visualiser (Produit Data Decision)
- soit mettre en œuvre des modèles d'apprentissage automatique (Produit Machine Learning)
📚 Lire notre article sur les produits data
Ce processus nécessite une plus grande créativité et, il faut le dire, des échecs. Cela implique un degré élevé d'incertitude et de fortes évolutions et ajustements tout au long du cycle de vie du produit. C'est la raison pour laquelle les méthodologies Agiles sont particulièrement adaptées et couronnées de succès. Elles facilitent tant l’engagement des équipes que la qualité et la régularité du delivery.
Mise en place de Scrum au sein d’une équipe data
S'appuyer sur la méthodologie Scrum a été bénéfique pour les équipes data accompagnées par Hubvisory. Elle permet d’asseoir un certain nombre de repères (sprints réguliers de réalisation, management visuel, cérémonies...) qui apportent rythme et amélioration continue à l’équipe data.
Scrum divise la construction des produits en phases plus petites appelées sprints qui durent entre 1 et 4 semaines. Chaque sprint est donc timeboxé : il doit atteindre des objectifs et la réalisation de livrables ou incrément définis lors du sprint planning, réunion de lancement du sprint. Scrum s’appuie fortement sur les feedbacks utilisateurs.
📚 Lire notre article sur Scrum
📚 Lire notre article sur les sprints agiles
Quels sont les avantages et inconvénients d’une telle méthode?
👍 Pros :
- Permet le focus sur les utilisateurs : à chaque fin de sprint lors de la revue, on écoute et tient compte du feedback utilisateur.
- Adaptation & flexibilité : le feedback utilisateur nous permet d’adapter le prochain sprint et d’ajuster nos développements et donc notre modèle si besoin.
- Régularité : les limites temporelles rigides des sprints permettent aux équipes de s'habituer à une cadence de travail régulière.
- Collaboration : les cérémonies permettent de réunir régulièrement autour d’une table ou d’une visio toute l’équipe et ainsi de favoriser les échanges. Nous avons remarqué une nette amélioration de l’entraide, de la productivité et de l’engagement, d’autant plus avec la mise en place de bonnes pratiques comme le pair ou mob-programming.
- Responsabilité et confiance : chaque membre se sent responsable envers le reste de l’équipe. Ceci est renforcé par la nature transparente de Scrum et des pratiques telles que les daily meetings et les revues de sprint où les membres de l'équipe démontrent constamment leur travail.
- Pour les produits Data Machine Learning tout particulièrement, optimisation de la performance des modèles.
Nous détaillons finalement les avantages de Scrum en général mais qui sont tout particulièrement bénéfiques à une équipe data.
🤔 Cons :
- Phase d’estimation moins évidente : quelques problèmes dans la phase d’estimation car dans certaines phases du développement, il s’agit de travailler avec de nombreuses inconnues
- Trop de rituels ? les équipes Data souvent peu habituées aux cérémonies agiles peuvent se plaindre du temps occupé par ces rituels qui semblent empiéter sur leur temps de développement.
- Une “Definition Of Done” (DoD) difficile à définir : pour rappel, la DoD est une liste de critères définis par l'équipe déterminant si une User Story peut se considérer comme terminée. L’objectif de la DoD est d'assurer la qualité des réalisations. Or, ce défi est particulièrement redoutable pour les équipes data. En effet, une grande partie du travail de l’équipe, surtout dans les premières phases d’exploration, n’est pas destinée à être diffusée en dehors de l’équipe. Nous recommandons d’organiser un atelier avec toute l’équipe data pour définir en co-construction cette liste de critères qui peut varier selon la catégorie de User Story (flux/API, visualisation, SQL, Machine Learning, front…).
- Des User Stories techniques : si l’on s’en tient aux définitions strictes des User Stories techniques et fonctionnelles, en effet les produits data peuvent présenter un grand nombre de User Stories techniques. Nous conseillons néanmoins d’y recourir le moins possible en essayant de mettre en avant l’impact des développements sur l’utilisateur dans une User Story fonctionnelle et d’y attacher des tâches techniques. Et si la User Story technique est inévitable, rédigez-la en binôme avec un profil data.
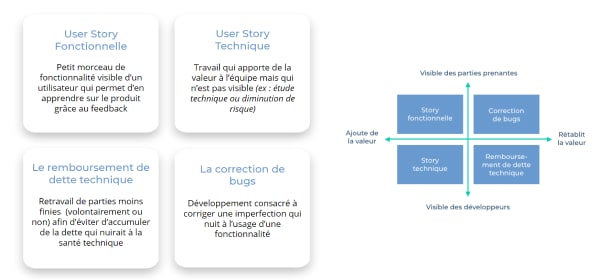
_Les différents types de User Stories_Source : Hubvisory
📚 Lire notre article sur la Definition of Done et la User Story
Adapter la méthode
Oui, Scrum est une bonne solution pour la réalisation d’un produit data.
Néanmoins, il ne s’agit pas d’appliquer Scrum à la lettre comme dans une équipe classique. Le Data Product Manager doit adapter les rituels et les artefacts au cas particulier de son équipe data et de son produit. Typiquement, un Data Product Manager sera peut-être amené à modifier le template des Users Stories, à y ajouter des informations propres au domaine de la Data Science. La construction d’un cycle de vie adapté des User Stories peut également être nécessaire afin de répondre aux exigences des produits data. Le plus important est de construire un fonctionnement qui convient à son équipe (et donc construire ensemble via des ateliers par exemple), qui vous permet d’être performant et de livrer des fonctionnalités qualitatives.
Par exemple dans nos missions, nous avons en effet été confronté lors des cérémonies d’Affinage et de Poker Planning à une équipe de développement peu à l’aise à l’idée d’estimer certaines User Stories de nature exploratoire par exemple. Et l’idée n’est pas de forcer un chiffrage inexact et altérer les performances de l’équipe.
Une solution que nous avons pu tester et valider est l’utilisation de Spike à la place d’une User Story pour se laisser un laps de temps afin de “craquer” les incertitudes. Un spike, c’est une notion qui existe déjà en Agilité : il s’agit d’une activité de recherche ou d’exploration réalisée avant la création d’une User Story. L’objectif d’un Spike est de réduire le risque et les incertitudes. Ce n’est donc pas une User Story à proprement parler, et le Spike est limité dans le temps.
Avant d'intégrer à un sprint une User Story difficile à estimer :
- Définir une période sur votre bande passante durant laquelle votre équipe va creuser un sujet (la bonne pratique étant maximum 2 jours). Ce temps va permettre de répondre à toutes les interrogations sur le sujet. A la fin de ce temps, quelles que soient les conséquences, on s’arrête !
- Ce spike peut générer plusieurs User Stories (techniques ou fonctionnelles).
Et quid de Kanban ?
Il est bien sûr possible de privilégier la méthodologie Kanban. Il faudra alors que l’équipe data réfléchisse à ses propres modalités, ainsi qu’aux outils et rituels nécessaires à l’accomplissement de ses objectifs.
Pour rappel, Kanban est une méthode de travail collectif basée sur la visualisation, la limitation du travail en cours, et l'amélioration incrémentale. Kanban utilise un tableau comme suivi de produit et des cartes comme tâches. Un tableau Kanban traditionnel comprend trois colonnes - Terminé, En cours et À faire. Pour un produit data, des colonnes supplémentaires peuvent être ajoutées.
Kanban présente une approche Agile, à l’image de Scrum. Néanmoins, cette méthode met davantage l'accent sur le “Work in Progress” sans la notion de sprint, ni l’application de tous les rôles et cérémonies : ce qui peut être un plus dans le développement de produits data selon les équipes.
📚 Lire notre article sur la méthode Kanban
En conclusion
Le Product Management peut s'adapter et est même essentiel pour les produits data : on parle de Data Product Management.
Nous vous rappelons les caractéristiques principales :
- Une phase d’exploration rigoureuse afin de valider la valeur du produit data ;
- Une approche itérative et incrémentale des problèmes, se basant sur un empirisme Test & Learn laissant la place à l’innovation ;
- Une concentration sur les utilisateurs, dont on recueille régulièrement le feedback ;
- Un fonctionnement Agile de l’équipe, qui pourra s’auto-organiser autour d’une communication conviviale et d’objectifs communs.
Pour aller plus loin
📚 Pour aller plus loin, quelques ressources :
Conférence Google “Designing Human centered AI products”
Un canvas pour explorer la valeur d’un produit data
En savoir plus sur les Spikes___


