
Chez Hubvisory, le Product Management est notre spécialité. Depuis quelques années, des Hubvisors épaulent nos clients sur un type de produit un peu particulier: le produit data.
Pourquoi s’intéresser aux produits data ?
Les produits data sont incontournables aujourd’hui du fait du Big Data. Un buzzword pour simplement mettre en évidence l’explosion du volume de données dont disposent les entreprises aujourd’hui. Un volume si important que son analyse dépasse les capacités humaines et celles des outils informatiques classiques. Ces données peuvent être de nature personnelle, professionnelle ou institutionnelle, elles peuvent provenir de différentes sources d’information circulant sur les réseaux numériques et ont différents formats (texte, vidéo, audio, base de données, etc.).
Selon McKinsey Global Institute, le volume mondial de données double tous les trois ans. L’essor des plateformes numériques (applications, sites web ..), capteurs sans fil, objets connectés, et les milliards de smartphones en circulation expliquent cette augmentation impressionnante.
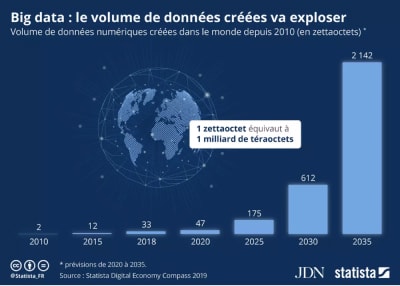
Evolution du volume de donnée dans le monde__Source:
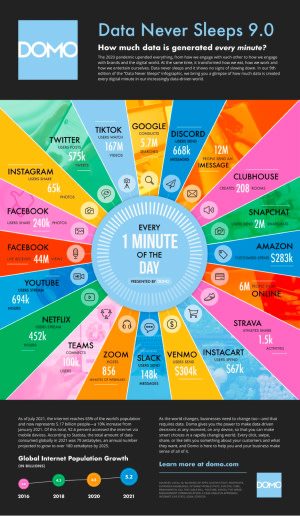
_Nombre de données générées et consultées sur Internet en 1 minute en 2021 (réseaux sociaux, plateformes de streaming, plateformes collaboratives)_Source:
De nombreux challenges accompagnent cette explosion des données réunis sous le concept des 5V :
- Volume : comme expliqué plus haut, volume vertigineux de données à gérer
- Vélocité : traitement de ces données en temps réel et donc rapidement
- Variété : ces données prennent de nombreuses formes (image, vidéo, post instagram, like, cookies, montant d’un panier, localisation ... )
- Véracité : ces données sont-elles pertinentes ? Reflètent-elle la réalité ?
- Valeur : parmi cet immense volume de données, tout ne présente pas de valeur. Il faut trier et sélectionner les données pertinentes !
Voilà pourquoi le développement de produit data est incontournable et que l’application d’une méthode adaptée du Product Management optimisera le succès de ce type de produit.
Comme tout Product Manager, le Data Product Manager doit maîtriser les spécificités du métier ainsi que les enjeux de la gestion d’un produit digital. Il doit également être sensible à l’environnement technique de son produit et aux problématiques associées.
De ce fait, il doit prendre un temps de formation afin d’acquérir une compréhension fonctionnelle et technique de la data. Cela lui permettra d’être à l’aise dans son quotidien, ses prises de décisions, ses échanges avec son équipe... [attention, lorsqu’on parle de technique il ne s’agit pas de savoir développer un modèle de Machine Learning]. Cela lui apportera du crédit auprès des profils data (ex : Data Scientist) avec qui il travaille mais également lui permettra de sensibiliser et dialoguer avec les parties prenantes de manière pertinente. Embarquement immédiat vers le monde merveilleux de la Data Science !
Qu’est-ce qu’un produit data ?
Pour bien comprendre ce qu’est le Data Product Management, il faut d’abord définir ce qu’est un produit data.
📚 Un produit data a pour objectif principal de transformer des données brutes en informations significatives et actionnables qui répondent à un besoin. Pour ce faire, le produit data combine de la programmation, des mathématiques, des statistiques. Il nettoie, transforme, visualise des nombres, des textes, des images, des vidéos, de l’audio (...) pour effectuer des tâches qui nécessitent habituellement l’intelligence humaine et servir un besoin utilisateur.
Dans cet article, nous distinguerons deux types de productions : les produits d’analyse (Data Decision) et les produits Machine Learning.
Les produits d’analyse - Data Decision
De nombreuses entreprises détiennent aujourd’hui un immense gisement de données en interne : il faut la récolter de manière qualitative, la stocker, l’afficher et la traduire pour la rendre compréhensible aux équipes métier.
Le produit Data Decision cherche à fournir des informations pertinentes à l'utilisateur afin de l'aider dans sa prise de décision (attention le produit ne prend pas la décision lui-même). Un travail conséquent est réalisé par ces produits afin de présenter ces informations dans un format facile à comprendre.
Voici quelques types de décisions pouvant être prises aujourd’hui grâce à des produits de Data Decision avec des exemples concrets de produits data associés.
Des décisions business et stratégiques
Avec les solutions de data visualisation (Google Analytics, PowerBI, QlikView, Tableau ou Flurry) : une entreprise peut décider d’un changement de stratégie éditoriale ou choisir un canal de diffusion d’une campagne marketing, ajouter ou supprimer un moyen de paiement sur son site e-commerce, trouver des solutions aux fuites dans l’entonnoir de conversion … Chez un de nos clients, nous avons développé un PowerBI présentant les performances des opérations commerciales. Il présentait le delta de trafic (en magasin et web) et de chiffre d’affaires qu’avait généré chaque opération commerciale. Cela permettait aux équipes en charge du choix et de la planification des opérations commerciales de renouveler ou non une opération d’une année sur l’autre par exemple.
Des décisions techniques et d’architectures
Avec les outils de monitoring ou d’alerting (DataDog, par exemple, permet de mesurer la performance, la disponibilité et l’intégrité d’un système applicatif). Le temps de réponse particulièrement long d’une page pourra provoquer la priorisation de User Stories de dettes techniques par exemple.
Les Dashboards disponibles et intégrés dans tous les outils du marché : JIRA, Salesforce, Gtmhub … proposent tous de la visualisation et de l’analyse des données. Par exemple, sur JIRA, visualiser l’évolution de sa vélocité au fil des sprints lèvera potentiellement des alertes et engendrera la mise en place d’actions.
Des décisions personnelles
Les comparateurs de prix (Skyscanner, Liligo, Google Shopping, Idealo, Kelkoo …) : décider de ses dates de vacances en fonction des jours où les billets d’avion seront les plus intéressants, choisir le moyen de transport, la compagnie aérienne, décider du site e-commerce sur lequel nous allons acheter cet appareil photo que l’on convoite etc
Les sites de rating (TripAdvisor, Google Reviews …) : quantitative (note globale) ou qualitative (commentaires précis), une revue vous a certainement déjà permis de choisir un restaurant, une activité etc
Les plateformes d’analyse et dashboarding :
- CovidTracker, par exemple, est une plateforme permettant de suivre l’évolution de l’épidémie de Coronavirus en France et dans le monde. Guillaume Rozier, fondateur, a également créé une seconde plateforme, “ViteMaDose”, permettant de trouver un rendez-vous de vaccination facilement en agrégeant tous les créneaux disponibles. Pour ces deux produits data, l’objectif est de transformer “des données complexes, avec beaucoup d’indicateurs et une volumétrie élevée dans des formats différents à quelque chose de simple et d’accessible pour le grand public”. Le jeune fondateur précisait lors d’un talk avoir été remercié par un directeur de centre hospitalier qui utilisait ces produits quotidiennement en cellule de crise à l’hôpital pour prévoir les besoins, notamment humains et en matériel.
- TradingView et tous les produits d’analyse boursier du genre proposent un grand nombre d’indicateurs techniques et de graphiques qui aident particuliers, professionnels et entreprises à définir des stratégies d’investissement.
Vous l’aurez compris, ces produits facilitent la prise de décision, en associant analyse de données et visualisation. Cela prend souvent la forme de dashboards, c’est pourquoi ce type de produit peut être plus facilement appréhendé par les Product Manager car il présente une interface avec l’utilisateur contrairement au produit Machine Learning présenté dans la partie suivante.
Les produits Machine Learning
Qu’est-ce que le Machine Learning ?
“L’analyse prédictive est un ensemble de techniques et d’outils qui permettent de formuler des prédictions statistiques à propos de phénomènes sociaux, économiques ou naturels à partir d’un historique de données représentatives. Elle permet de construire dynamiquement des modèles prédictifs directement à partir de jeux de données plutôt que l’élaboration manuelle de règles métiers figées”
Source : Big Data et Machine Learning - Les concepts et les outils de la Data Science (Edition Dunod)
Un produit Machine Learning intègre la mise en place d’un modèle grâce à de l’apprentissage afin de prédire : on parle d’apprentissage automatique.
Le Machine Learning se base sur des fonctions mathématiques qui, par itération et alimentation de nouvelles données, permettent de créer des algorithmes performants. A la différence de la Data Decision, le Machine Learning offre une réponse prédictive. Ces algorithmes d’apprentissage sont entraînés avec une large quantité d’exemples pour obtenir un modèle.
Pour s’assurer de la performance d’un modèle (sa capacité à faire les bonnes prédictions sur base de nouvelles données), on met en place des cross validations.
La méthode la plus simple de cross validation est la “holdout method”: On prend un jeu de données (dataset) qu'on va diviser en training set et testing set. Le training set permet d'entraîner l’algo et le test set, de juger de sa performance.
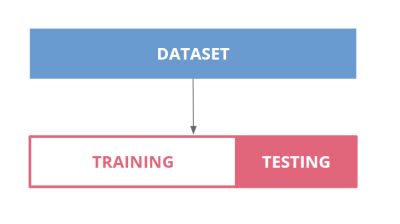
_Composition d’un dataset d’un produit Machine Learning_Source : Hubvisory
📚 Pour aller plus loin
Il existe des librairies d'outils dédiés au Machine Learning et à la Datacience dans l'univers Python, par exemple Scikit-Learn qui est la principale bibliothèque.
On vous a perdu ? Voici un exemple un peu plus concret.
Imaginons que vous souhaitiez construire un modèle capable de reconnaître la plus belle ville du monde (Lille, bien sûr) à partir d’une photo. Dans la phase d’apprentissage, vous constituez un training set de photos que vous envoyez à l’algorithme standard choisi :
- De Lille avec le label Vrai
- D’autres villes avec le label Faux
Une fois entraîné, vous passez à la phase de déploiement où vous envoyez cette fois des nouvelles photos aléatoirement de Lille et autres villes sans la réponse. Le modèle est alors en mesure de vous dire/prédire s’il s’agit de la plus belle ville du monde ou pas.
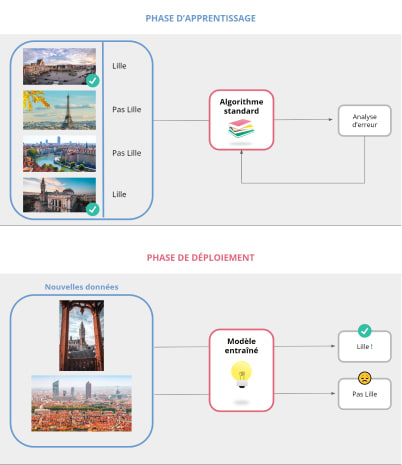
_Illustration de la phase d’apprentissage et de la phase de déploiement d’un produit Machine Learning_Source : Hubvisory
L’abondance et la qualité des données sont les clefs du Machine Learning. Plus on entraîne le modèle, plus ce dernier sera performant (i.e répondra juste). Le jeu de données doit donc être conséquent avec une répartition équilibrée de cas de succès, et de cas d’échec... Il doit avoir la couverture la plus large, être “propre”, et être complet. Par exemple, dans notre cas de plus belle ville du monde, il s’agit bien d’équilibrer son training set : si vous entraînez votre modèle qu’avec des photos de Lille, il ne sera pas très performant lorsque vous lui proposerez d’autres villes.
Le Machine Learning existe depuis les années 1950 mais son utilisation n’explose que depuis quelques années. A l’époque, les modèles étaient peu performants dû à la faible quantité de données à disposition (entre autres), aujourd’hui ce n’est plus le cas !
📚 Pour aller plus loin
Nuançons un peu le paragraphe précédent... Notamment lorsque nous évoquons l’abondance de données nécessaires à l'entraînement d’un modèle performant. Lorsqu’on développe un modèle de Machine Learning, il faut faire attention à ne pas être dans le sur-apprentissage ou overfit.
“L’overfitting est le risque pour un modèle d’apprendre “par cœur” les données d’entraînement. De cette manière, il risque de ne pas savoir généraliser à des données inconnues.”
Supervisé versus Non supervisé
Le choix de l'algorithme standard est une phase très importante dans la construction d’un produit data : il en existe un très grand nombre et on choisira en fonction du type de tâche que l’on souhaite accomplir et du type de données que l’on dispose.

_Différence entre apprentissage supervisé et non supervisé_Source : https://twitter.com/athena_schools/status/1063013435779223553
- Supervisé
Le training set mentionné plus haut est annoté dans le cas d’un algorithme supervisé. Chaque instance est associée à un label, l’équipe data dispose déjà d’étiquettes sur des données historiques et cherche à classifier des nouvelles données. L’exemple du modèle capable de reconnaître la plus belle ville du monde est basé sur un algorithme supervisé car nous l’avons entraîné à l’aide de photos taguées “Vrai” ou “Faux”.
- Non supervisé
Le training set n’est pas annoté, l’algorithme va donc regrouper les données en fonction de similarité de variable (aussi appelée feature). Il repère des motifs communs afin de constituer des groupes homogènes à partir de nos observations. Dans l’image plus haut, on cherche les similarités entre deux variables : le poids et la couleur dominante par exemple.
Des produits Machine Learning intégrés tout au long du parcours utilisateur
Un exemple très commun de produit Machine Learning est le moteur de recommandation (Google, Netflix, Amazon …), qui ingère les données des utilisateurs et génère des recommandations personnalisées basées sur ces données.
Pour aller un peu plus loin, nous vous proposons de nous appuyer sur une plateforme (un peu) connue, Airbnb, pour mettre en évidence l’omniprésence des produits Data dans notre quotidien. Tout au long de l’expérience utilisateur sur la plateforme, des produits Data Science utilisant du Machine Learning sont en action. En voici ci-dessous quelques exemples :
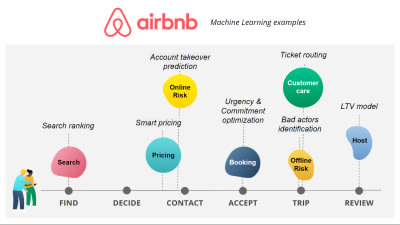
_Des produits data tout au long du parcours utilisateur @Airbnb_Source : Hubvisory
- Dans la phase de recherche de voyage, l’utilisateur utilise la fonctionnalitée “Research” qui fait appel notamment à un produit Machine Learning appelé “Search Ranking”. Cet algorithme est capable de suggérer et classer des biens «pertinents» à l’utilisateur grâce aux données historiques.
Pour aller plus loin, je vous invite à consulter cet article détaillé concernant le Research ranking des expériences.
- L’algorithme de Smart Pricing aide les hôtes à fixer le prix de leur bien en location avec des recommandations basées sur les données des autres biens similaires déjà présents dans la plateforme.
- Lors de la réservation d’un séjour, un autre produit Machine Learning permet d’optimiser les messages U&C - Urgency & Commitment (exemple : “Ce logement est très demandé, c’est une pépite, il est normalement réservé à cette période …”). Le Machine Learning permet de connaître la fréquence à laquelle est réservé tel logement et quelle est la probabilité qu’il soit réservé dans les prochaines heures, les prochains jours …
- Pour répondre aux problématiques de risques offline, un produit Machine Learning basé sur le profil des utilisateurs identifie les utilisateurs “dangereux” (similaire aux produits de détection de fraude très répandus).
- Afin d’améliorer le service client, le Machine Learning permet d’acheminer les tickets urgents ou importants à la bonne équipe au bon moment.
- Pour finir, un produit appelé Jumeau permet de détecter les potentielles doubles annonces qui peuvent être publiées par des hôtes frauduleux souhaitant échapper aux limitations de nuits imposées par chaque ville. Une fois les doublons détectés, ils sont envoyés à une équipe d’agents qui, manuellement, vérifiera si oui ou non il s’agit véritablement d’un double frauduleux. Ces labels vrai/faux vérifiés sont alors utilisés pour nourrir le modèle de Machine Learning du produit afin d’améliorer ses performances de détection.
Ces exemples de produits Machine Learning disséminés tout au long du parcours utilisateur permettent de comprendre concrètement leurs applications et leurs enjeux mais également de mettre en évidence l’existence de produits data non visibles qui apportent de la valeur à l’expérience de vos utilisateurs.
Une entreprise ou un produit digital a tout intérêt à intégrer ce type de produit afin d’anticiper certains comportements humains et ainsi obtenir un avantage compétitif sur ses concurrents.
D’autres types de produit data ?
Il existe bien sûr d’autres types de produits data.
Par exemple, les produits Data Engineering. Ils ont pour objectif de connecter les outils entre eux et de mettre à disposition de la donnée pour des utilisations diverses (Business Intelligence, Data Science...). Ils forment l’infrastructure robuste, connectée et interopérable qui permet la disponibilité, l’intégrité et la confidentialité des données de l’organisation.
Quelles différences entre un produit classique et un produit data ?
Qu'il s'agisse d'un produit complet destiné au client ou d'un produit back-end partiel, le produit data présente des caractéristiques différentes des produits classiques.
Un produit data traite de données inconnues menant à des résultats non connus. Les sujets data demandent beaucoup de recherche, d’exploration, de test et de transformation.
Par exemple, il s’agit d’explorer de manière “large” les données qu’on soupçonne pertinentes pour le projet mais suite à cette phase d’exploration, certaines données seront écartées, peut-être toutes et cela orientera la suite du travail des Data Analysts et Data Scientists. La construction d’un produit data est un enchaînement de recherche, échec, ajustement etc.
Un produit classique, au contraire, présente des données structurées avec des résultats connus : l’équipe de développement sait déjà ce qu’elle souhaite construire.
En conclusion
Aujourd’hui, nombre de produits data sont en échec. En effet, la data, le Machine Learning sont “à la mode” mais le développement de tels produits reste complexe, coûteux et ne doit pas être pris à la légère.
Comme tout produit, le produit data doit répondre à un besoin utilisateur pour rencontrer le succès : c’est pourquoi appliquer les principes sur Product Management est tout aussi essentiel dans le développement de ce type de produit.
Nous creuserons dans le prochain article pourquoi les produits data sont pour beaucoup en échec et comment adapter les méthodes du Product Management pour leur développement.
📚 Pour aller plus loin, quelques ressources :


